Vision-language model (VLM) agents are increasingly deployed in interactive game environments. Yet game benchmarks for VLM agents typically report a single first-attempt score per (agent, game) pair, focus on single-agent Solo play, and lack unified protocols for evaluating heterogeneous agent classes (commercial VLMs, open-weight VLMs, and specialized game policies) on the same footing.
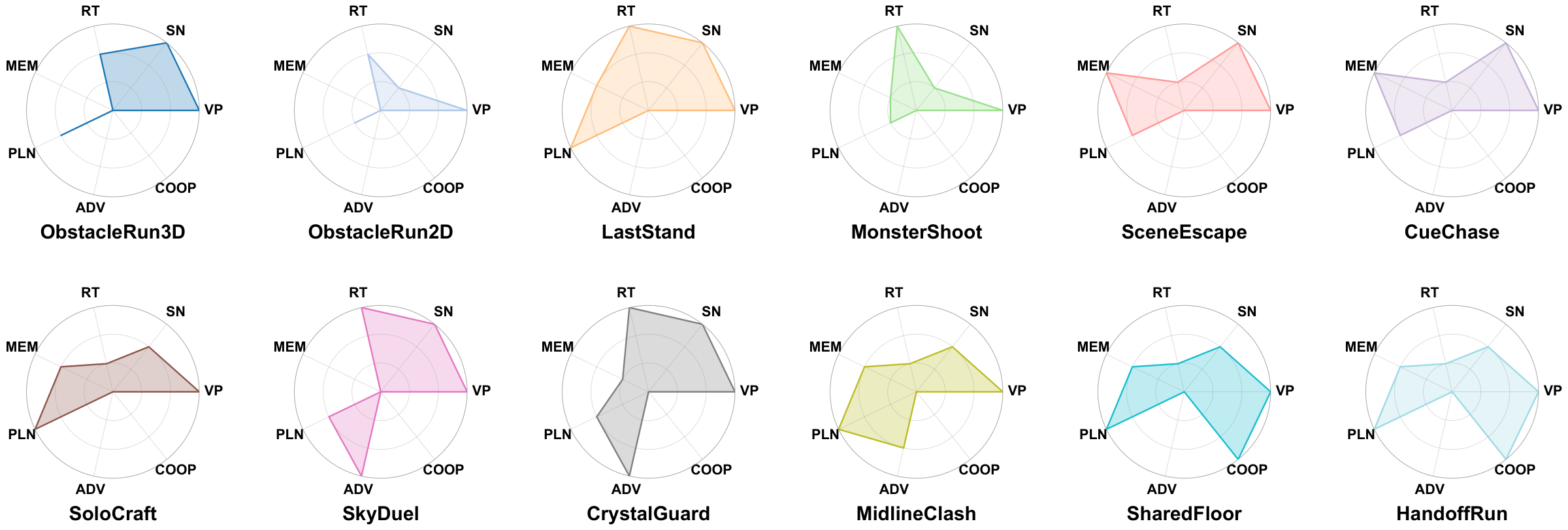
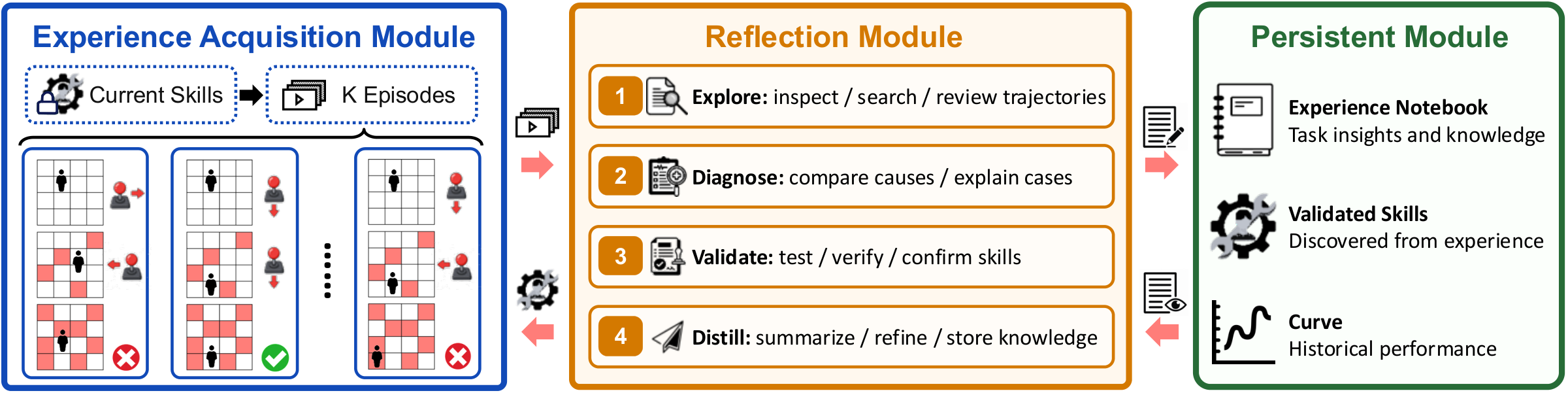
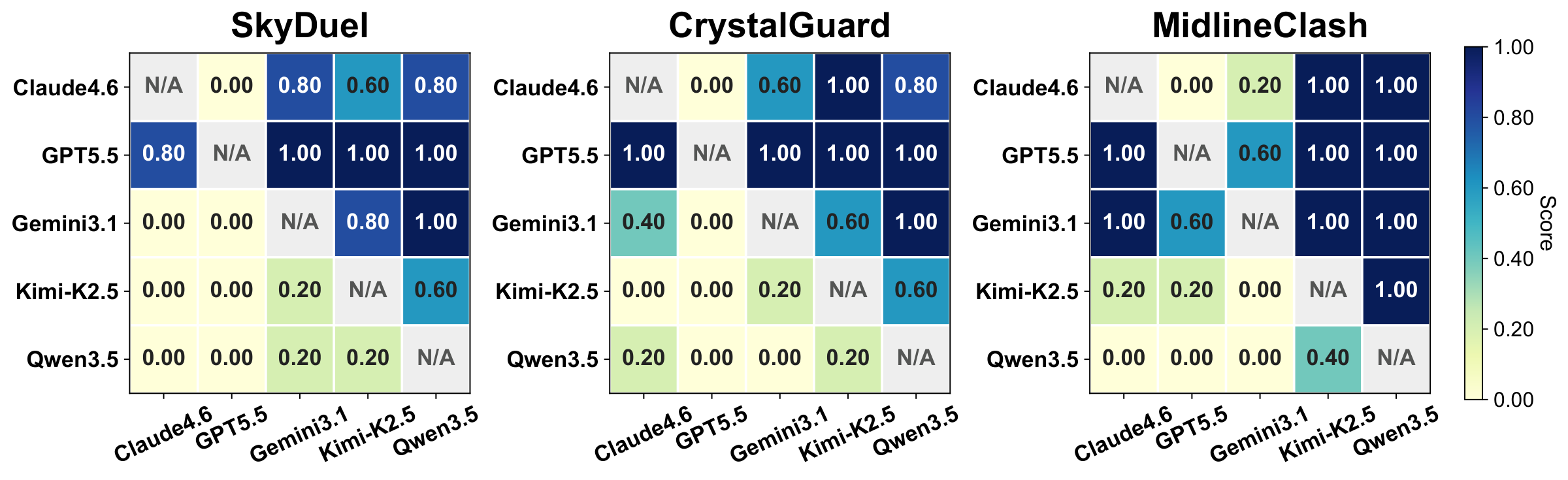
We address these gaps with OmniGameArena, a real-time benchmark of twelve newly built Unreal Engine 5 games spanning Solo (7), PvP (3), and Coop (2) with unified action interfaces, and the Improvement Dynamics Curve (IDC), an agentic-reflection harness in which a tool-using reflector LLM autonomously refines a bounded skill prompt across multiple rounds. Beyond cold-start leaderboard scores, IDC exposes two additional observables for each (agent, game) pair: how the score evolves across reflection rounds, and how the learned skill behaves on held-out task variants. We report these observables for twelve VLM agents on the cold-start leaderboard and four top agents under IDC.